




















Big companies, to roll their updates without even a single second of downtime, is it possible to roll our updates on the fly without the client coming to know even if he is using the application ? Can we make all of this automated ? Yes we can, and that’s the biggest need of today’s market.
Our requirement is to roll out all the updates without downtime.
We are ready to push his code to GitHub and we as devops engineers are ready to pull the code using the CI/CD tool, Jenkins. We use the method of building remote triggers to inform Jenkins about the same.
As soon as the developer pushes the code , using the post-commit (GitHub Hook) our jenkins would come to know that the file has been pushed and its time to go and get it downloaded in its workspace
What is our requirement from Job1?
Job1 would first of all download the GitHub code and what next? It would dynamically create the image for the application for which the developer pushed the code which in our case is Webserver. That is, we need our job1 to create an image for webhosting and obviously, copy the code into the required directory inside our webserver container. And also, after creating the image will push this image to the docker registery so that everyone publically could access it.
For this purpose we are providing a Dockerfile by which Jenkins would build an image for Webserver.
The above commands would first allow the dockerfile to take the code uploaded by the developer and deploy it in the webserver and then for pushing your image to the public registry ie. the docker hub. For that you first need to login by the “ docker login “ command where you need to provide the username and password for your docker hub account and then the “docker push “ command to push the image.
Our job1 is complete !!! Now it’s time to proceed and create a dynamic slave node setup with the configured kubernetes kubectl command . And for that we create another Docker file which will be used to create an image for kubernetes slave (the dynamic slave).
We are using Kubernetes to manage our containers because if a container dies or get corrupted docker itself won’t be able to bring it up again. So for the smart management of containers we need Kubernetes. The services that we are going to use is Deployment.
|
FROM ubuntu:16.04 RUN apt-get update && apt-get install -y openssh-server RUN apt-get install openjdk-8-jre -y RUN mkdir /var/run/sshd RUN echo 'root:redhat' | chpasswd RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config # SSH login fix. Otherwise user is kicked off after login RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd ENV NOTVISIBLE "in users profile" RUN echo "export VISIBLE=now" >> /etc/profile #kubectl setup RUN apt-get install curl -y curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl RUN chmod +x ./kubectl RUN mv ./kubectl /usr/local/bin/kubectl EXPOSE 22 CMD ["/usr/sbin/sshd", "-D"] |
Why is it important to have dynamic setup in this agile world? In real world we would always have limited computing power ie. CPU/RAM/Storage and therefore we create a setup that the user would have just one endpoint to which it would connect but behind the scene we would be using the slave nodes just for their computing power which indeed would make our process faster and would allow us to run many jobs in parallel. The dynamic slave node setup would allow us to launch the node as and when the demand comes and use it for running the jobs. when the demand is fulfilled the slave node is terminated on the fly.
So before configuring the slave node we need to make some changes inside our docker, because the tool that is used behind the scene for setting up slave nodes is docker.
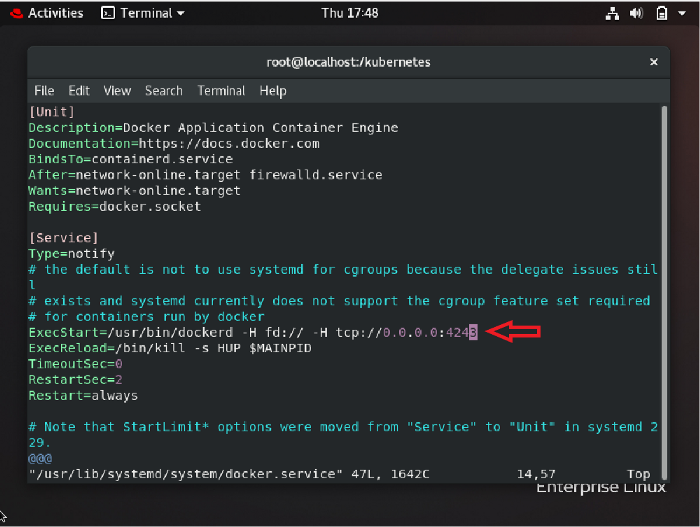
We need to edit this in the docker configuration file so that anybody from any IP can connect with docker at the specified port. Now, you can configure the slave node in the following way.
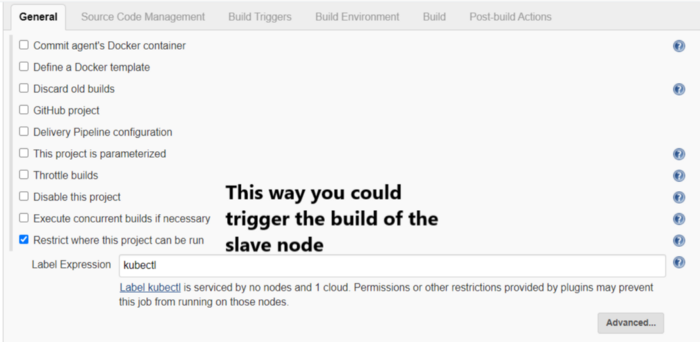
Manage Jenkins — Manage nodes and clouds — Add a new cloud
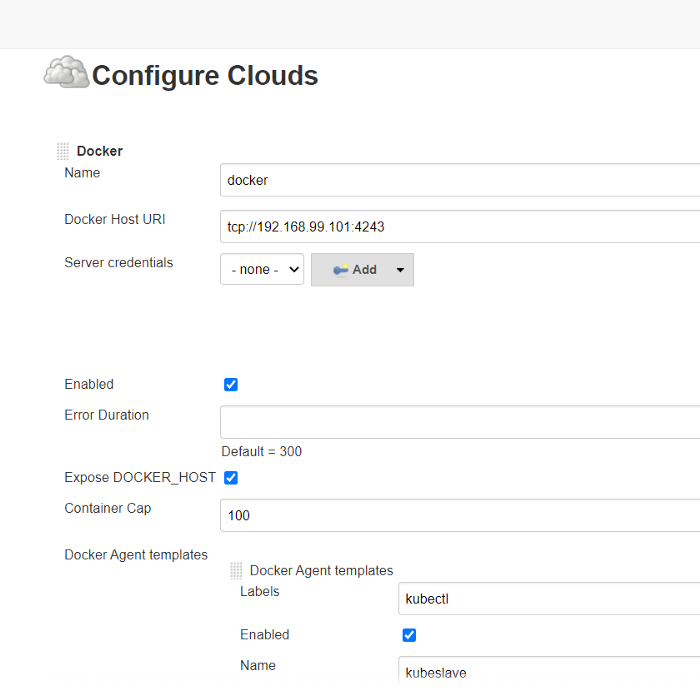
Along with these steps you also need to specify the volume ie. where all the files that are needed to run the kubectl are kept which are ca.crt, client.key ,client.crt and config file for kubectl.
Now for the deployment and the service configuration we created two config files:
deployment.yaml
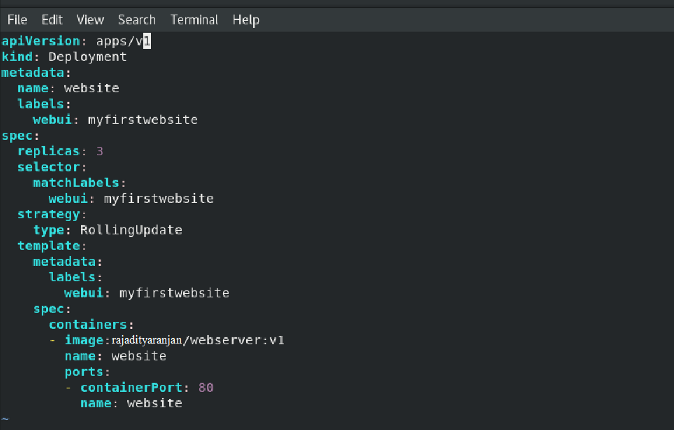
service.yaml
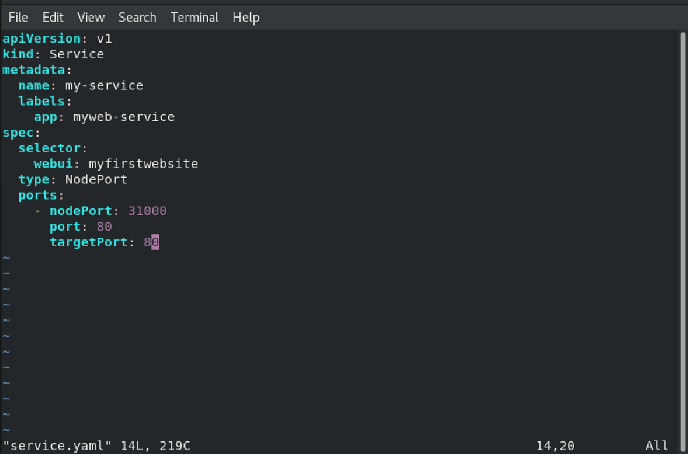
Now we are ready to deploy our website using pods in Kubernetes. When job2 would start it would trigger the creation of the slave node with the required label. Then job 2 will do its work of deploying the pods as per requirement
The commands written in the execute shell are the following:
|
sudo sed -i "s/image.*/image: khushi09\/test:${BUILD_NUMBER}/" /kubernetes/deployment.yaml if kubectl get deployment | grep website then kubectl replace -f /kubernetes/deployment.yaml else kubectl create -f /kubernetes/deployment.yaml fi |
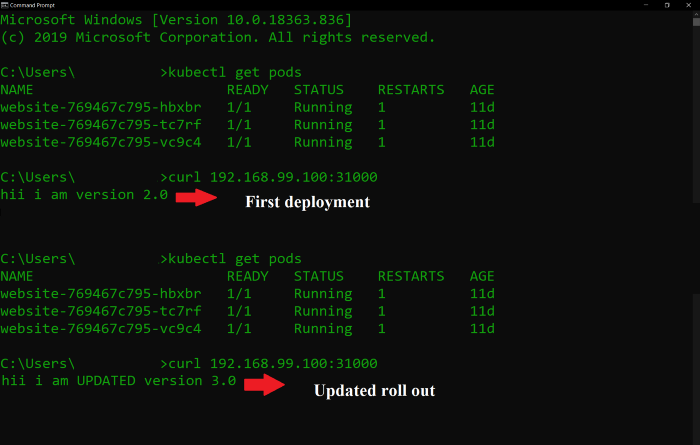
This creates the deployment and for rolling update replaces the deployment and the pods if they already exist.
Final Output

![]()
![]()
![]()
![]()
![]()
![]()



